《多易教育|码龙 Flink教程》
课程配套文档 PART2
4 flink常用transformation算子
4.1 map映射(DataStream → DataStream)
输入一条,经过变化,输出一条;
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
// source
DataStreamSource<String> ds = see.socketTextStream("doitedu01", 8899);
SingleOutputStreamOperator<LogBean> res = ds.map(new MapFunction<String, LogBean>() {
@Override
public LogBean map(String value) throws Exception {
LogBean logBean = null;
try {
String[] arr = value.split(",");
logBean = LogBean.of(Long.parseLong(arr[0]), arr[1], arr[2], Long.parseLong(arr[3]));
} catch (Exception e) {
logBean = new LogBean();
}
return logBean;
}
});
res.getParallelism();
res.print() ;
see.execute("map") ;
}
// SingleOutputStreamOperator<String> ds2 = ds.map(String::toUpperCase);
// SingleOutputStreamOperator<String> ds3 = ds2.map(String::toLowerCase).setParallelism(16);4.2 flatMap 压平映射
Takes one element and produces zero, one, or moreelements. A flatmap function that splits sentences to words
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1) ; // 设置全局并行度为1
DataStreamSource<String> lines = see.fromElements("学 大数据 到 多易 教育", "找 行哥", "不吃亏");
SingleOutputStreamOperator<String> res = lines.flatMap(new FlatMapFunction<String, String>() {
// 每条数据执行一次这个方法
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split("\s+");
for (String word : words) {
out.collect(word);
}
}
});
res.print() ;
see.execute() ;
}4.3 filter过滤
针对每个摄入的数据进行条件判断 .符合条件的数据返回
Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.setInteger("rest.port", 8888);
StreamExecutionEnvironment see = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);
see.setParallelism(1) ; // 设置全局并行度为1
DataStreamSource<Integer> ds = see.fromElements(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
/* SingleOutputStreamOperator<Integer> res = ds.filter(new FilterFunction<Integer>() {
@Override
public boolean filter(Integer value) throws Exception {
// 处理每条数据 将满足条件的数据返回
return value > 5 && value%2==0;
}
});
*/
SingleOutputStreamOperator<Integer> res = ds.filter(e -> e > 5 && e % 2 == 0);
res.print();
see.execute() ;
}4.4 普通function 和 RichFunction的比较
在各类需要传入Function的算子中,基本上都可以接收两种Function:
- 普通Function
- RichFunction
其中,RichFunction会多出open() 和 close() ,以及 getRuntimeContext() 这几个从AbstractRichFunciton所继承来的方法;
这样,我们可以在自定义的XXRichFunction中,利用或重写这些方法,来实现更多的功能;
比如,在open中,我们可以安排一些初始化逻辑,在close方法中,可以安排一些释放资源的逻辑;
而用getRuntimeContext(),则可以利用返回的runtimeContext来获取状态、注册定时器等;
api使用示例如下:
5 常用sink算子
5.1 Kafka sink
将流数据,写入kafka
5.2 Jdbc sink
将流数据,用jdbc的方式,写入外部数据库(如 mysql、oracle、db2、sqlServer 等支持jdbc的数据库)
6 高阶算子
6.1 process算子
process算子中的ProcessFunction是RichRunction,因此可以利用RichFunction的一切功能;
process算子中的ProcessFunction,还支持通过ctx获取timerService来使用定时器功能;
6.2 window窗口算子
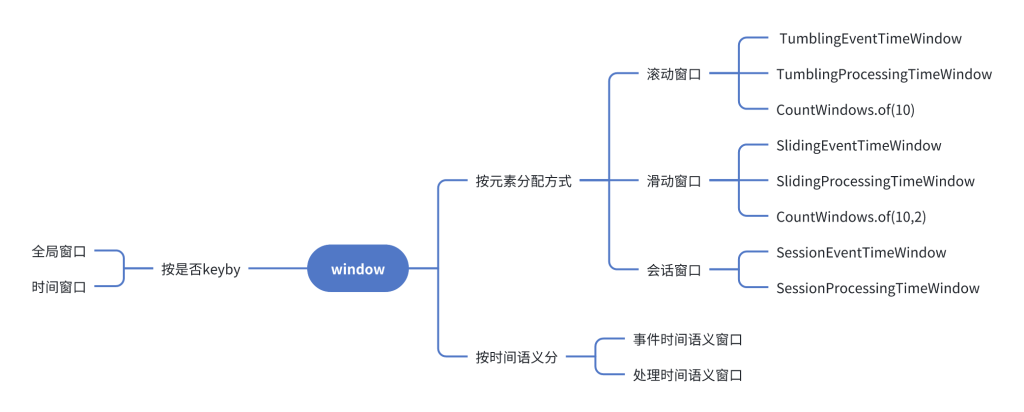
6.2.1 窗口分类
windows算子,就是把数据流中的数据划分成一个一个的窗口,然后进行计算;
flink中窗口有两种大类型:
- Count Window: 以数据条数来划分窗口;比如每 10 条 划分到一个窗口;
- Time Window:以时间来划分窗口;比如每10分钟划分一个窗口;
TimeWindow中还有一些子类:
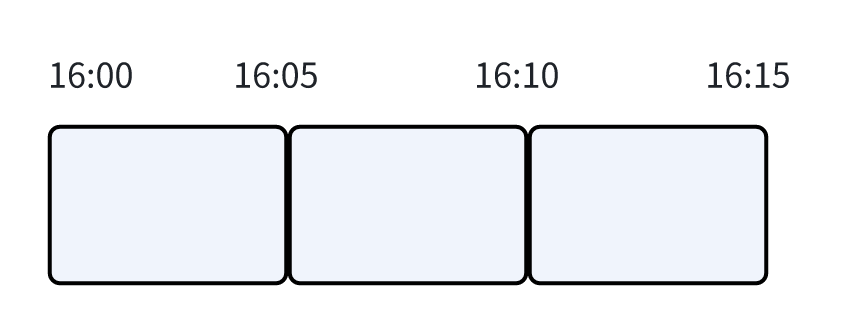
- 滚动窗口:前后两个窗口没有重叠;
比如:每5分钟一个窗口; [10:00-10:05), [10:05-10:10)

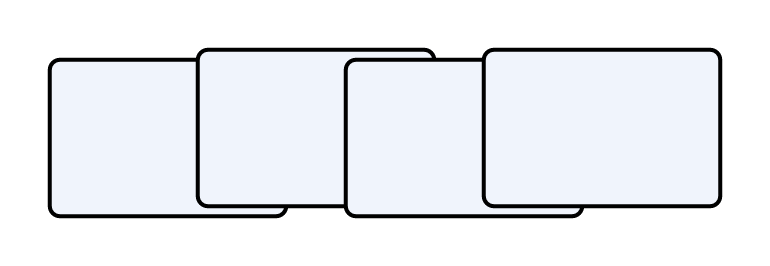
- 滑动窗口:前后两个窗口有重叠;
比如:窗口长度为5分钟,滑动步长为2分钟;
[10:00-10:05), [10:02,10:07)
- 会话窗口:遇到相邻两条数据的时间间隔超出会话Gap,则划分窗口

从另外一个角度来划分:
- 全局窗口 (全局窗口计算的算子,在运行时,只会有一个并行度)
- keyed窗口
6.2.2 窗口api模板
keyed窗口
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"Non-keyed 窗口
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"6.2.3 窗口聚合算子
开窗之后,必须调用如下算子,才能形成计算逻辑任务;
全量聚合算子
特点:算子的Function中,在窗口触发时,会拿到窗口的全量数据来进行计算
- process[ProcessFunction(context, elements ) ]
- apply
滚动聚合算子
特点:flink底层会来一条数据就聚合一下,到窗口触发时,输出结果
- aggregate
- reduce
- min、max
- minby、maxby
- sum
6.3 多流操作算子
6.3.1 connect
stream1.connect(stream2)
一次调用,只能是2个流连接;参与连接的流可以是不同的类型;
后续调用的算子传入的Function,都是CoFunction,里面都有两个数据处理的方法
比如,CoMapFunction
CoMapFunction {
状态
返回统一类型 map1(流1的数据)
返回统一类型 map2(流2的数据)
}6.3.2 窗口join
api模板
stream
.join(otherStream).where(<KeySelector>)// 左流的关联key.equalTo(<KeySelector>)// 右流的关联key.window(<WindowAssigner>)// 开窗.apply(<JoinFunction>); // 为能关联的数据生成结果6.3.3 union
stream1.union(stream2,.....)
要求:参与合并的流可以是多个流,必须是相同类型的;
后续调用的算子传入的 Function,就是普通的单流 Function了
比如: MapFunction
返回类型 map(各个输入流的数据)6.3.4 窗口cogroup
stream1.coGroup(stream2)
.where(OrderMain::getOrderId) // 指定流1中的关联条件字段
.equalTo(OrderItem::getOrderId) // 等于 流2中的关联条件字段
.window(TumblingProcessingTimeWindows.of(Time.minutes(1)))
.apply(new CoGroupFunction<OrderMain, OrderItem, String>() {
@Override
public void coGroup(Iterable<OrderMain> first, Iterable<OrderItem> second, Collector<String> out) throws Exception {
// first : 是本次窗口左表的所有数据
// second: 是本次窗口右表的所有数据
}
})6.3.5 自实现“非窗口”join
flink自带的join算子,是约束在一个一个的窗口中关联
而这种窗口关联,每次窗口触发时,才执行关联逻辑;此时,窗口中的数据已经确定,所有输出的结果也是确定;
但我们自己开发的join逻辑,不限定在窗口中;
而是,不论左、右两表的数据到达时间差有多少,我们都要关联触结果;
这样,我们的结果是动态变化的;
比如左表右a,右表没有;我们就输出: a,null
后续,右表的a也来了,我们还得输出正确结果: a, a ,同时还要向下游传达信息,撤回: a, null这一条
所以,在这样的join场景中,我们输出的结果应该是一个 :变更日志流 ,changelog stream
7 其他算子
7.1 分区算子
并行计算: 都有分区的概念 ; 实时流处理数据过程中, 分区规则一般不需要参与 ,不同的算子调用时, 上游下游Task 合理的划分数据
分区算子:用于指定上游task的各并行subtask与下游task的subtask之间如何传输数据;
Flink中,对于上下游subTask之间的数据传输控制,由ChannelSelector策略来控制,而且Flink内针对各种场景,开发了众多ChannelSelector的具体实现 ; 数据分发规则, 一般不需要我们参与 ,调用不同的转换算子内部有具体的数据分发规则!
7.1.1 keyBy
DataStream → KeyedStream
逻辑上将流划分为不相交的分区(一条记录仅且只分到一个组中)。
具有相同键的所有记录都分配给同一个分区。
在内部,keyBy 是通过哈希分区实现的。
7.1.2 其他分区算子
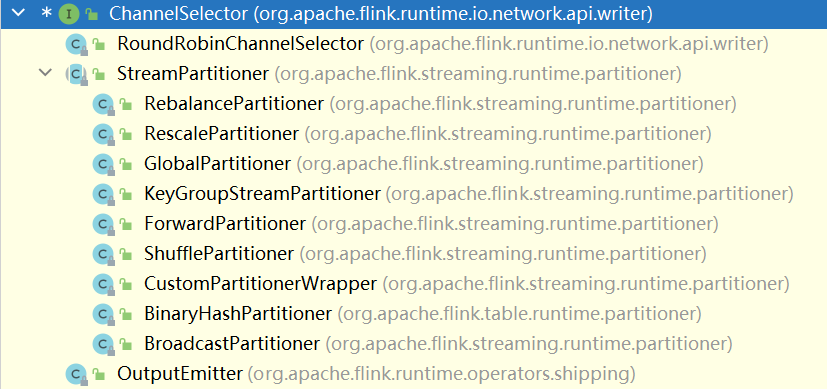
设置数据传输策略时,不需要显式指定partitioner,而是调用封装好的算子即可:
| ds.global() | 上游所有Subtask的数据都发往下游Task的第一个Subtask |
| ds.broadcast() | 上游每个ST的所有数据都会发往下游每个ST |
| ds.forward() | 上下游数据是一对一分发 |
| ds.shuffle() | 上游数据随机发送到下游 |
| ds.rebalance() | 轮循发送数据 |
| ds.recale() | 本地轮循发送数据 |
| ds.partitionCustom(自定义分区器) | 自定义数据分发规则 |
| ds.hash() | key的hash值 % X 分配数据 |
7.1.3 侧输出流算子
DataStream<Integer> input = ...;
final OutputTag<String> outputTag = newOutputTag<String>("side-output"){};
SingleOutputStreamOperator<Integer> mainDataStream = input
.process(new ProcessFunction<Integer, Integer>() {
@Override
public void processElement(
Integer value,
Context ctx,
Collector<Integer> out) throws Exception {
// emit data to regular output
out.collect(value);
// emit data to side output
ctx.output(outputTag, "sideout-" + String.valueOf(value));
}
});7.1.4 广播算子
public class Demo36_BroadcastDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
// 构建一个kafkaSource对象
KafkaSource<String> source = KafkaSource.<String>builder()
.setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.LATEST))
.setGroupId("g001")
.setClientIdPrefix("flink-c-")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setBootstrapServers("doitedu01:9092,doitedu02:9092,doitedu03:9092")
.setTopics("od")
.build();
// 用env使用该source获取流
DataStreamSource<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "随便");
stream.broadcast().map(s->s).setParallelism(3).print().setParallelism(3);
env.execute();
}
}